
昨今、技術トレンドの一つとして、AIが流行っています。
しかし、これまでのAIといえば何となく玄人向けというイメージが強く、一般的には「人間の仕事が奪われる」とか「よく分からないけど色々なアプリに入っている」といった抽象的なイメージが多かったと思います。

2022年の11月30日に「ChatGPT」がリリースされました。
2023年2月に安定版がリリースされ、誰でも手軽に会話できるAIが誕生したということで様々なメディアで話題となり、現在では密かにムーブメントが起こっています。
Microsoftの検索エンジンサービス「Bing」が検索機能でChatGPTを使えるようにしたことや、Googleがそれに追随し、独自に開発を進めていた対話形のAIサービス「bard」を同社の検索エンジンで使えるようにしていくと発表されたこと、Notionが日本語での形態素解析が得意なNotion AIをリリースするなど、対話型AIがますます身近な存在となってきました。
今回はそんな「ChatGPT」について、現時点で約2ヶ月間使ってみた筆者が、その概要と今後の展望について記事を書きます。
NotebookLMで作成したPodcastのような音声概要です。チームメンバーと共有したい方やお忙しい方、タイパを優先させる方におすすめです!
※漢字や英単語の読み方については、一部誤りもあることをご容赦ください。
この記事のインデックス
はじめに
まずはじめに、このブログの構成や記事の一部はChatGPTによって作成されました。
しかし、彼が書いた記事そのままではいくつか問題点があるため、あくまでもそれをベースに構成を組み立て、サポートしてもらいながら文章を完成させています。
アイキャッチの画像のように、決してロボットが書いている記事ではないことを、最初に断っておきます。
ChatGPTとは何か?
ChatGPTは、人工知能技術の一つで、自然言語処理の分野で注目されているモデルです。
「OpenAI」によって開発された「ChatGPT」は、大規模なデータセットを学習することで文章の生成や自然言語による対話を可能にしました。
ChatGPTは人間とのコミュニケーションにおいても高い精度を発揮し、現在、多くの企業や研究機関で利用されています。

「OpenAI」は、人工知能を責任を持って安全に発展させることを目的とした研究機関です。
テスラCEOのイーロン・マスクやサム・アルトマンなど著名なテックリーダーたちによって2015年に設立され、人類に有益な形でAIを発展させることを目的としています。
ChatGPTの”GPT”とは、Generative Pre-trained Transformer の略称であり、自然言語処理における重要な技術の一つです。現在組み込まれているのは、2020年7月にOpenAIが発表した高性能な言語モデル「GPT-3」です。
言語モデルとは、人間が話したり書いたりする言葉を単語の出現確率でモデル化したものです。
この言語モデルは、一般的に大量のテキストデータを使って事前に学習したベースモデルをもとに、テーマに合わせた専用の再学習(これを「ファインチューニング」と言います)をすることで精度を高めます。
しかし、この再学習には教師データ(例題と答えのデータ)を使うため、そのデータの準備に多大な労力がかかるという課題があります。
GPT-3ではどうやって学習してるの?
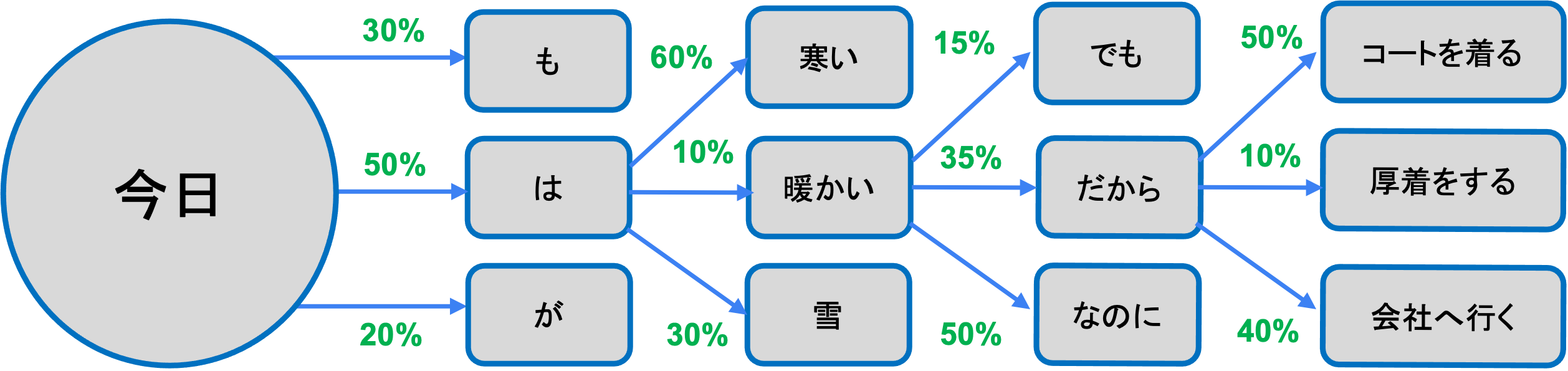
これに対してGPT-3では、とても膨大なテキストデータを用いて学習することで、ファインチューニング を必要としない言語モデルを作り出しています。
GPT-3は、Wikipedia やWebサイトから収集されたデータなどから集めた45TBもの膨大なテキストデータに対し、いくつかの前処理を行った570GBのデータセットを学習に用いています。
このデータセットに対して、さらに1750億個のパラメータを持つ自己回帰型言語モデル(ある単語の次に出てくる単語を予測するモデル)を学習することで、これまでにない巨大な言語モデルを形成しています。
このように、大量のデータを使用して学習されたChatGPTは高い精度で文章を生成し、自然言語による対話を実現することができているのです。
まず、文章の開始部分を与えると、ChatGPTはその文脈を理解し、自然言語のルールやパターンに基づいて、次に出現する可能性のある単語やフレーズを予測します。
そして文脈や話題に応じて、適切な言葉を選択し、流暢な文章を生成します。
また、ChatGPTは応答生成にも使用され、与えられた質問に対してまるで人間のように自然な応答を生成することができます。
自然言語処理(NLP)
このようにChatGPTは、自然言語処理の分野において、その高い精度と柔軟性からますます重要な役割を果たすことが期待されています。
自然言語処理(NLP)とは、人工知能が人間が使用する自然言語を解析し、理解するための技術です。
つまり、NLPはコンピュータに言葉を教える分野といわれています。
GPTは自然言語処理(NLP)における機械学習の一つで、大量の文章データから自然言語のルールやパターンを学習することができ、文章生成や応答生成、文書の分類、言語翻訳など、様々なタスクをこなしているのです。
ChatGPTをチャットボットとして活用する
ChatGPTはその高度な自然言語処理の能力から、チャットボットとして利用されることがあります。
チャットボットは自動応答システムであり、人工知能を用いて自然言語でのコミュニケーションを行うことができます。
そこにChatGPTを使用することで、チャットボットはより自然で流暢な応答を生成することができます。

例えば、カスタマーサポートのチャットボットに使用する場合、ChatGPTは質問や問題に対して、まるで人間のような自然な応答を生成することができます。
また、ChatGPTは多様なトピックに対しても応答できるため、顧客との会話の幅を広げることができます。
今後ChatGPTは、チャットボットとしての利用方法において、その高い精度と柔軟性から、ますます重要な役割を果たすことが期待されています。
文章起こしに使ってみる
ChatGPTはテキスト生成においても利用されます。
テキスト生成によって文章やフレーズを自動生成することで、広告や自動要約、自動記事生成などの分野で使用することが期待されます。

ChatGPTは、これまでのAIより自然で流暢な文章を生成することができます。
例えば、記事生成の場合、ChatGPTにテーマを与えることで、そのテーマに沿った自然な文章を生成することができます。
冒頭で述べた通り、まさにこのブログ記事にChatGPTを採用しています。
さらに、テキスト生成において柔軟性が高く、与えられたテーマに対して多様なアプローチをとることができるため、より多様な文章を生成することができます。
今後ChatGPTは、テキスト生成の分野において、その高い精度と柔軟性から、ますます重要な役割を果たすことが期待されています。
もちろん限界もある
構造モデルとしての限界
これまで書いてきたとおり、ChatGPTは自然言語処理の分野において、非常に高い性能を発揮しています。とはいえ、限界も存在します。
まず一つ目の限界は、大量のデータを必要とすることです。
ChatGPTは、そもそも巨大なトレーニングデータセットを使用してトレーニングされていますが、それでもデータが不足する分野においては、パフォーマンスが低下することがあります。
例えば、画像のキャプションや機械翻訳など、他の種類の自然言語処理タスクには、より適したモデルが存在するからです。
また、ChatGPTはテキスト生成に特化しているため、日本語の形態素解析には対応しておらず、自然言語処理の他のタスクには適していない場合があります。
形態素解析とは、自然言語で書かれた文を言語上で意味を持つ最小単位(=形態素)に分け、それぞれの品詞や変化などを判別することです。
同じGPT-3を使って、この日本語での形態素解析をおこなえるサービスが「Notion AI」です。
20回以上は有料となってしまいますが、非常にクオリティの高い文章を生成してくれます。
私の場合、ChatGPTのみを使うのではなく、Stable DiffusionやD-IDを組み合わせるなどして、画像生成や動画生成などにもチャレンジしています。
偏ったデータが引き起こす問題
ChatGPTのトレーニングに使用されるデータは非常に重要であり、データが何らかの方向に偏っていると、そのパフォーマンスに大きな影響を及ぼします。
例えば、性別や人種に基づく偏りがあるデータセットを使用すると、モデルがバイアスを持つことがあります。

これは、生成された文章や回答が、特定の性別や人種に偏っている可能性があることを意味します。
そのため、トレーニングに使用するデータセットには、多様性が求められるのです。
また、トレーニングに使用されるデータセットが時代遅れである場合にも、モデルのパフォーマンスが低下することがあります。
例えば、ChatGPTがトレーニングに使用するデータが2019年のものである場合、2023年の現在では、多くの新しい言葉や表現が存在しているため、そのような言葉や表現を含む文章を生成することができません。
データセットの選択はモデルのパフォーマンスに大きく影響するため、慎重に行われる必要があります。
ChatGPTの未来
今後どのように進化していくのか?
ChatGPTはその高いパフォーマンスから、今後も発展を続けることが期待されています。
その一つの方向性として、より大規模なデータセットを使用して、より複雑な文章や文脈を理解することができるようになることです。
また、多言語対応や異なるドメインに対応することで、応用範囲を拡大することが期待されています。
その結果として、ChatGPTが単にテキスト生成に限定されることなく、自然言語理解や対話システムの分野にも応用されることが期待されています。

例えば、自然言語理解の分野では、ChatGPTを用いたテキスト分類や質問応答、意味解析などがあります。
また、ビジネス分野においては、ChatGPTを用いた顧客対応や、自動応答システムの開発が進んでいます。
医療分野では、ChatGPTを用いた病気の診断や治療方針の提案、病気に関する情報提供が期待されています。
その他にも、教育分野や芸術分野など、様々な分野において、ChatGPTの応用が進んでいくことが期待されています。
GPT-4の登場
いよいよ、GPT-4が発表されました。
GPT-4では、入力としてテキスト、オーディオ、ビデオ、および画像をサポートします。
人間はテキストや言葉のみならず、相手の身振り手振りなど、様々な情報を処理して状況を見出すわけですが、これらをマルチモーダルと言います。GPT-4は、テキストに加え、動画や音声、画像データを処理して、このマルチモーダルをサポートするようになるということです。
これにより、GPT-4は録音した声を学習して顧客とのやり取りを学習したり、動画に記録された事象から答えを導き出してくれるようになるということです。
ただ、マルチモーダルになると、よりノイズも多くなるわけで、それらのどの情報を優先的に処理するかといった信頼メトリックに取り組む必要があるでしょう。
まとめ
ChatGPTは、現在の自然言語処理分野において、非常に重要な位置を占めています。
従来の自然言語処理の手法では、複雑な文脈やニュアンスを理解することが難しく、高度な人工知能の実現には限界がありました。
しかし、ChatGPTの登場により、膨大な量の自然言語データを学習することで高度な自然言語理解を実現することができるようになりました。
今後、ChatGPTが持つ可能性は非常に大きく、自然言語処理の分野において、様々な応用が期待されています。
例えば、ChatGPTを用いた人工知能エージェントの開発により、人間と自然な対話を行うことが可能になりますし、ChatGPTを用いた自動翻訳システムにより、異なる言語間のコミュニケーションも容易になる可能性があります。
さらに、ChatGPTを用いた自然言語処理技術により、ビッグデータ解析や情報抽出など、様々な分野に応用が期待されています。
今後、AIがますます発展し、人間が今よりも高度なジョブをより的確に、そしてスピーディーにこなせるようになる未来が待っているのではないでしょうか。